
En un trabajo publicado por unos investigadores del University College y el Alan Turing Institute de Londres se cuantifica hasta qué punto los metadatos que incluyen los mensajes en las redes sociales pueden utilizarse para identificar usuarios concretos – sin siquiera analizar el propio contenido del mensaje. Las pruebas las han hecho con Twitter. Y han concluido que incluso ofuscando gran parte de esa información los algoritmos de aprendizaje automático son capaces de acertar el 95% de las veces.
El trabajo se titula You are your Metadata: Identification and Obfuscation of Social Media Users using Metadata Information [PDF] y en él se describen los datos que se analizan y los algoritmos con los que se puede conseguir esa identificación. Aunque las pruebas se han hecho con Twitter todas las redes sociales dejan rastro de los usuarios en esos metadatos, así que esto vale para todos.
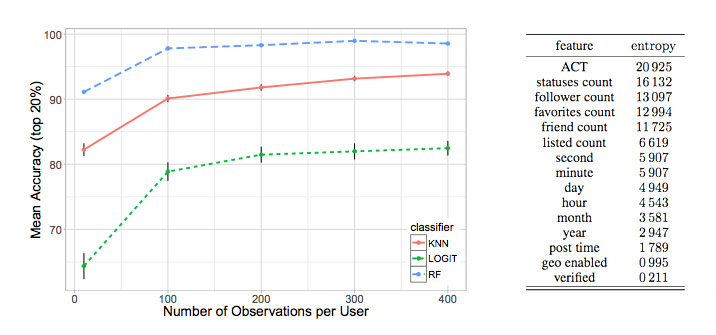
En concreto en Twitter cada mensaje lleva asociados metadatos tales como la fecha de creación de la cuenta, el número de seguidores, la cantidad de favoritos que ha dado esa cuenta, si tiene geolocalización activada o no, en cuántas listas públicas aparece, la fecha y hora en que se publicó cada tuit, si la cuenta es verificada o no, cuántos tuits ha publicado… En total hasta 14 elementos distintos.
Podría pensarse que con cientos de millones de usuarios registrados estos datos no servirían de gran cosa de cara a identificar a alguien concreto, pero al contrario: no es complicado entrenar a algoritmos de aprendizaje automático para luego «acertar» de quién procede un tuit si se les muestra uno al azar. Eliminar algunos de esos metadatos tampoco sirve de mucho porque el porcentaje de acierto sigue siendo asombrosamente alto.
(Vía Jorge Morell.)

En un trabajo publicado por unos investigadores del University College y el Alan Turing Institute de Londres se cuantifica hasta qué punto los metadatos que incluyen los mensajes en las redes sociales pueden utilizarse para identificar usuarios concretos – sin siquiera analizar el propio contenido del mensaje. Las pruebas las han hecho con Twitter. Y han concluido que incluso ofuscando gran parte de esa información los algoritmos de aprendizaje automático son capaces de acertar el 95% de las veces.
El trabajo se titula You are your Metadata: Identification and Obfuscation of Social Media Users using Metadata Information [PDF] y en él se describen los datos que se analizan y los algoritmos con los que se puede conseguir esa identificación. Aunque las pruebas se han hecho con Twitter todas las redes sociales dejan rastro de los usuarios en esos metadatos, así que esto vale para todos.
En concreto en Twitter cada mensaje lleva asociados metadatos tales como la fecha de creación de la cuenta, el número de seguidores, la cantidad de favoritos que ha dado esa cuenta, si tiene geolocalización activada o no, en cuántas listas públicas aparece, la fecha y hora en que se publicó cada tuit, si la cuenta es verificada o no, cuántos tuits ha publicado… En total hasta 14 elementos distintos.
Podría pensarse que con cientos de millones de usuarios registrados estos datos no servirían de gran cosa de cara a identificar a alguien concreto, pero al contrario: no es complicado entrenar a algoritmos de aprendizaje automático para luego «acertar» de quién procede un tuit si se les muestra uno al azar. Eliminar algunos de esos metadatos tampoco sirve de mucho porque el porcentaje de acierto sigue siendo asombrosamente alto.
(Vía Jorge Morell.)